那本篇就來進入到本地部屬llm的部分!
將模型部屬至本地執行有很多方法,這邊已meta的Llama3為例,可以用Ollama平台,或是HuggingFace的transformer,也可以直接去meta的官方申請,再去它們的github專案下載。
我們今天就先來介紹使用Ollama來部屬本地模型。
先來介紹一下Ollama這個平台
ollama是一個for AI 開發者的平台,他讓大語言模型(LLM)使用和開發所需要做的流程簡化直觀很多。提供了一個直觀的環境來運行、創建和管理模型,支援多個作業系統,包括 macOS、Linux, Windows 等等。
他能夠自動檢測使用最佳硬體配置,像是 NVIDIA GPU ,使 model 高效運行,不需要使用者做額外的配置。ollama 裡還有很完整的模型庫,像是自然語言處理和影像識別等等,讓 user 能輕鬆使用如 llama、gemma 等熱門模型。此外,Ollama 提供內建的 Always-On API,便於開發者將許多 AI model 的功能使用整合到自己的一些應用中,簡化了開發過程,讓開發者可以快速上手。
那我們就馬上開始用吧!
首先先去官網將SetUp檔載下來,依據PC的作業系統選擇
下載完並開始SetUp安裝完後,我們就可以開始在terminal(cmd or powershell)使用了!
首先我們先輸入下載模型的指令
ollama pull ModelName
就可以將想要的模型下載下來了,然後輸入
ollama list
就可以看到本地現有的模型
那假如想要指定模型的版本,例如想指定llama3-8b的,就要
ollama pull llama3:8b
這樣就可以指定版本了! 假如沒指定的話就是下載他們預設的版本,通常是7b左右
那想要查看可以用的model可以到這裡查看(https://ollama.com/library)
接著我們輸入
ollama run ModelName
就可以開始運行模型了,在這邊就可以直接輸入,得到模型的輸出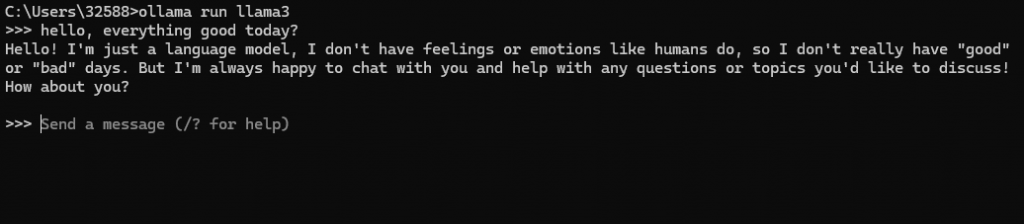
這就是最基本的使用ollama部屬本地模型並和模型交互的方式了,是不是很簡單呢?
之後我們就會帶到ollama其他與模型的交互方式,已完成更多的應用!

